Last mod: 2025.01.11
Raspberry Pi - Speech to text based on Vosk
Hardware and Software
- Raspberry Pi 4
- External USB microphone CAD Audio U9 USB MiniMic
- Vosk a speech recognition toolkit

Microphone
The Raspbery Pi does not include a built-in microphone. For this reason, we have to use an external one connected via USB. In the example I use the CAD Audio U9 USB MiniMic.
First we need to check that the system detects the microphone:
lsusb
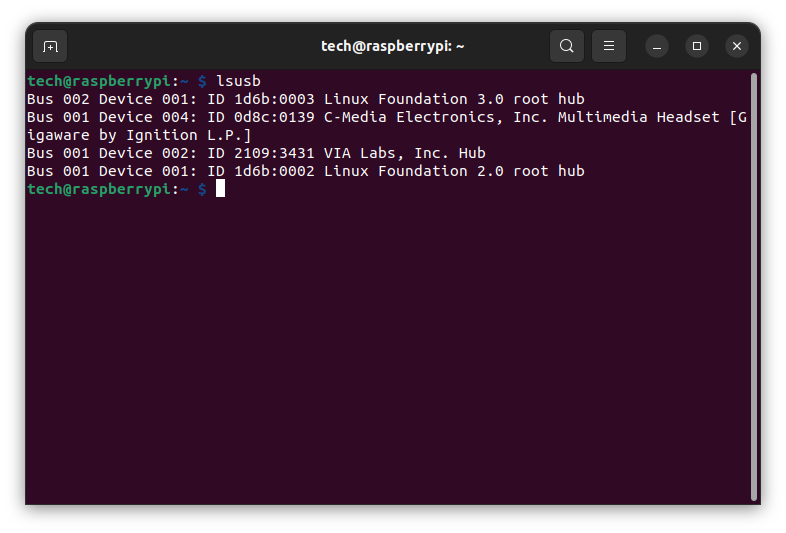
The device of interest is:
Bus 001 Device 004: ID 0d8c:0139 C-Media Electronics, Inc. Multimedia Headset [Gigaware by Ignition L.P.]
Vosk installation
Prepare and run dedicated enviroment:
python3 -m venv env_vosk
source env_vosk/bin/activate
Install required libraries and Vosk:
sudo apt install portaudio19-dev
pip install pyaudio vosk
Create directory form model and app example:
mkdir RaspberryPi_SpeechToText
cd RaspberryPi_SpeechToText/
Download and unpack small English model:
wget https://alphacephei.com/vosk/models/vosk-model-small-en-us-0.15.zip
unzip vosk-model-small-en-us-0.15.zip
Create Python file vosk_app.py:
import os
import sys
import wave
import json
import pyaudio
from vosk import Model, KaldiRecognizer
model = Model("vosk-model-small-en-us-0.15")
audio = pyaudio.PyAudio()
stream = audio.open(format=pyaudio.paInt16, channels=1, rate=16000, input=True, frames_per_buffer=8000)
stream.start_stream()
recognizer = KaldiRecognizer(model, 16000)
print("Please speak up...")
while True:
data = stream.read(3000)
if recognizer.AcceptWaveform(data):
result = recognizer.Result()
print(json.loads(result)["text"])
And run:
python3 vosk_app.py
Wait few secont and test, say "hello world" or other short sentence. Example result:
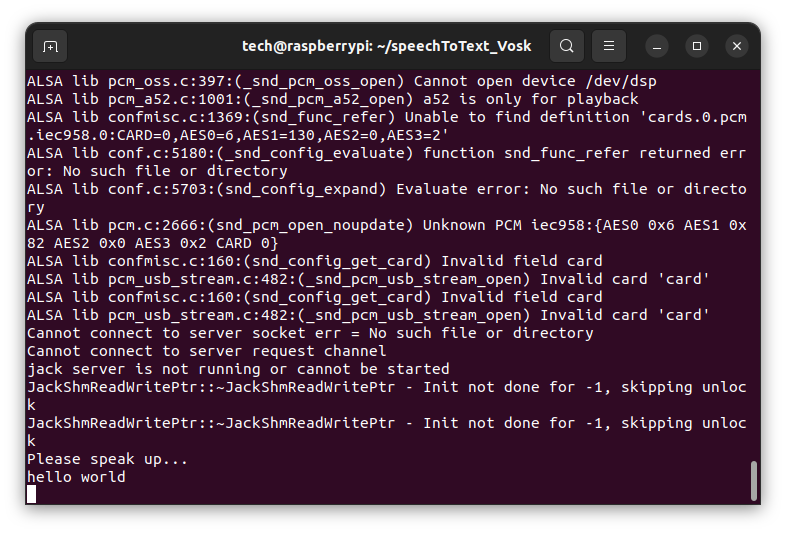
Links
https://www.cadaudio.com/products/product-application/u9
https://alphacephei.com/vosk/
https://alphacephei.com/vosk/models
https://gitlab.com/dziak.tech/examples/-/tree/main/IoT/RaspberryPi_SpeechToText